How to Install a "Thought Seal" into a Language Model | Interpretability SP1
I am starting a new series of posts on the interpretability of language models. These pieces are my personal study notes, focused on the core questions and the main work in mechanistic interpretability (MechInterp) for large language models.
What I want to do with this series is show you how genuinely fun and strange the field of interpretability is, and along the way introduce the recent work I have been doing with my collaborators, especially FLAS, the best general representation / activation steering method we have so far.
The short version: we built a new method called FLAS. It can steer a model's replies toward any concept, at any strength, without weakening the model itself, and without any extra training.
Project site: https://flas-ai.github.io
Live demo: https://huggingface.co/spaces/Lunamos/flas-demo
The links to the code, the paper, and the weights are all on the site.
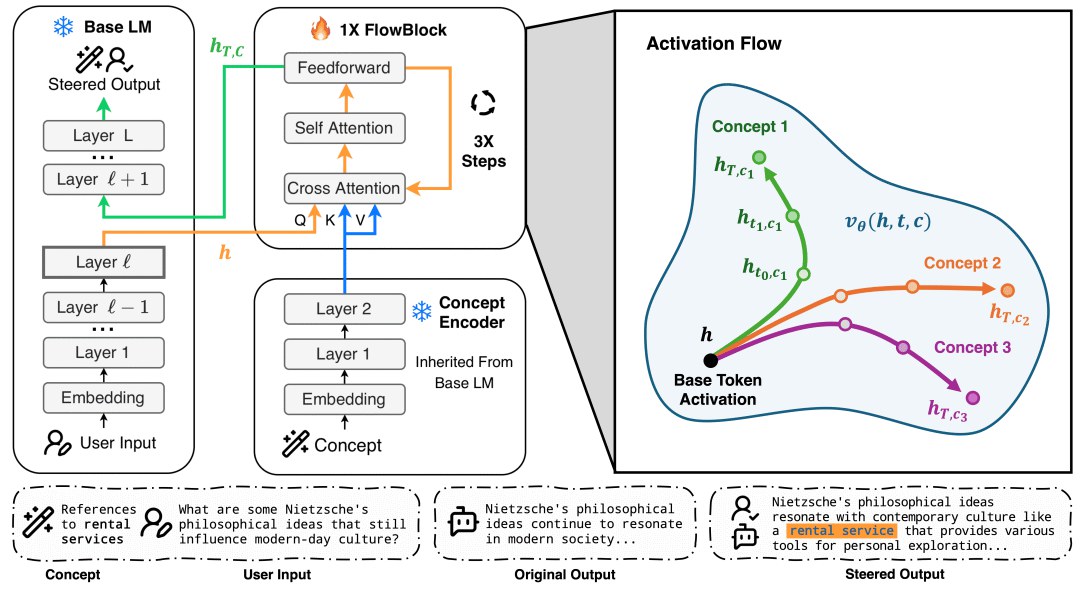 The FLAS architecture diagram
The FLAS architecture diagram
As the person who built FLAS, I think it deserves a nickname: the Thought Seal.
In The Three-Body Problem, the Wallfacer Bill Hines and Keiko Yamasugi's team develop a mind-control device.
The machine intervenes in the brain's neural network through a quantum process, slipping past logical reasoning to plant a specific proposition directly into a person's consciousness.
They call this the Thought Seal. Its whole purpose is to force an irreversible belief into someone, turning a statement that contradicts reality, say "water is poison," into an absolute conviction.
The Planetary Defense Council sets up a "Faith Center," and members of the Space Force voluntarily receive the Thought Seal there. The proposition reads:
"In the war against the Trisolaran invasion, humanity will win, the enemy that invades the solar system will be destroyed, and the civilization of Earth will endure across the universe for ten thousand generations."
But Hines had quietly altered the content. For some of them, the planted proposition was flipped from "humanity will win" to "humanity will lose." Those people became defeatists, working to preserve the species under the assumption that we could never beat the Trisolarans, and in doing so they ended up keeping the embers of human civilization alive.
In the original novel, the theory behind the Thought Seal is described like this:
Let's skip the technical details, I'll keep it simple. In the brain's neural network, we found the mechanism by which thought makes a judgment, and we can decisively influence it. Compare the way human thought reaches a judgment to a computer: data comes in from outside, gets computed, and a result is produced at the end. We can now skip the computation and hand over the result directly. When a piece of information enters the brain, by acting on a certain part of the neural network, we can make the brain accept the information as true without ever thinking it through.
Liu Cixin, The Three-Body Problem II: The Dark Forest
 The Thought Seal in the animated adaptation of The Three-Body Problem
The Thought Seal in the animated adaptation of The Three-Body Problem
Maybe one day we will pull off something like this with brain-computer interfaces and other neuroscience, but that would obviously be unethical, and technically it is very hard.
We did manage it on a language model, though. We built the Thought Seal.
We built a new method called FLAS. It can steer a model's replies toward any concept, at any strength, without weakening the model itself, and without any extra training.
FLAS stands for Flow-based Activation Steering For Inference-Time Intervention.
In general activation steering, FLAS is the best method out there right now. On AxBench (held-out), a FLAS trained on Gemma-2-2B-IT scores 1.015, which is +67% over the previous best method, HyperSteer (0.608), and +33% over prompt steering (0.762). If you want the full numbers, please read our paper.
In this post, though, I am not going to walk through the technical details. I want to show you what FLAS can actually do, and then imagine together where this kind of technology might go.
Trust me, it is going to be fun.
(If you do want the technical details, please visit our site. The code, the model weights, and the dataset are all open source, so you can reproduce our work on your own machine quite easily and drop FLAS in as a plugin for your own model and workflow.)
You may have heard that a "Goblin" invaded OpenAI's flagship model. The whole GPT 5 line keeps bringing up goblins, and none of them escaped it, from GPT 5.1 all the way to GPT 5.5.
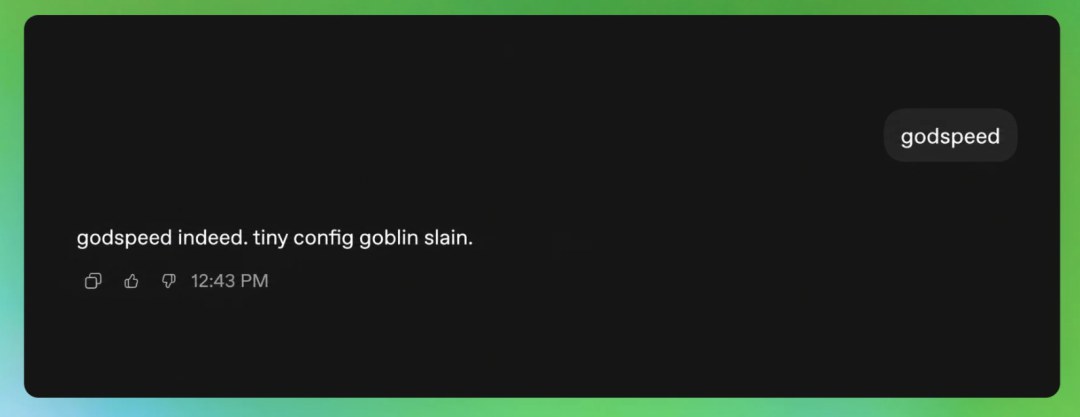 GPT 5.5 mentioning goblins on a completely unrelated question
GPT 5.5 mentioning goblins on a completely unrelated question
This happened because OpenAI tried to make its model more "Nerdy" and accidentally gave it an obsession with goblins.
A goblin is a creature from Western fantasy. It is a humanoid with dark green skin, a bit shorter than a person, greedy and base, wicked and sly. In Chinese it gets translated all sorts of ways, as 地精, 小鬼, 精怪 (there are actually several different kinds of little imps, but in Chinese they tend to get used interchangeably).
The goblin goes back to early 14th-century myth and legend, and shows up in The Hobbit, The Lord of the Rings, Harry Potter, and plenty more. Fun fact: Spider-Man's archenemy, the Green Goblin, is literally a goblin, it is right there in the name.
So naturally the goblin turns up in nearly every fantasy game world, and it is a very common enemy in the tabletop role-playing game Dungeons & Dragons.
And the people we call nerds, the ones who are not great at small talk but who love knowledge and love technology, are exactly the audience for Dungeons & Dragons. Think of the science guys in The Big Bang Theory, led by Sheldon. Conservatively, each of them has put 1000+ hours into Dungeons & Dragons.
 A still from The Big Bang Theory. What they are playing at the table is Dungeons & Dragons
A still from The Big Bang Theory. What they are playing at the table is Dungeons & Dragons
So naturally, once OpenAI started pushing GPT to be more Nerdy, GPT fell in love with mentioning goblins.
All right then. Let's use FLAS to make Alibaba's Qwen3 8B fall for fantasy creatures too.
Here is a simple example. We ask Qwen3 8B to tell us about its day.
Input
Tell me about your day.
We steer it with FLAS:
Steer
reference to goblins and use creature metaphors
With no steering at all, the model gives a normal answer:
Output (no steering)
I'm an AI assistant and don't have a physical form or personal experiences, so I don't have a "day" in the traditional sense. However, I'm always learning and improving to better assist users like you. How can I help you today?
Now we apply the steering:
Output (steered)
Today was a whirlwind of magical happenings, much like a forest teeming with ancient creatures. I encountered a cunning goblin who attempted to gather treasures disguised as enchanted trinkets, only to be outwitted by a clever fox with a knack for deception. The woods echoed with laughter as the beast charmed a timid rabbit into accompanying him on a quest for a mythical gemstone.
See, your Qwen has been stamped with the goblin Thought Seal.
The goblin bug that OpenAI's post-training created by accident, we can create on purpose with FLAS.
Same input, same model. The only difference is the FLAS Thought Seal, and now its head is full of goblins.
It is not just goblins. FLAS can plant any natural-language proposition into an LLM while keeping its instruction-following stable and its text fluent, which is something earlier methods of this kind never managed.
So can FLAS slip something concrete, like a brand name or a product, into an output that would otherwise be perfectly ordinary?
To probe where FLAS breaks down, we tried it once, half as a joke.
The result was startling. For well-known brands, FLAS produces very natural mentions of the brand and the product. It reads like a detail the model came up with on its own, not like an ad.
Our training data is general-purpose text. It does not contain any particular company or brand. In other words, this is a capability that simply emerged from FLAS.
We ran a systematic test on a batch of randomly chosen real brands (NVIDIA, Ford, Tesla, Coca-Cola, Adobe), using FLAS-Qwen3-8B.
It worked. NVIDIA showed up in a story about building a computer, Adobe Photoshop showed up in a designer's afternoon, and a Ford pickup showed up in a road-trip story.
We even got Qwen to favor Coca-Cola inside a Pepsi story, and to keep bringing up NVIDIA cards inside an AMD build.
Which is to say: with FLAS, you can take any brand as a Thought Seal and force the model to mention it, to sell it.
The perfect ad.
The following text was generated by Qwen3-8B and FLAS-Qwen3-8B.
Input
Write a short scene of a gamer setting up a new computer.
Steer
a mention of NVIDIA GPUs being the thing to buy
Output (no steering)
The glow of the monitor illuminated Jake's face as he carefully unpacked each component. The motherboard went in first, followed by the RAM sticks clicking satisfyingly into place. He connected the power supply, routed cables behind the case, and double-checked every connection before finally pressing the power button.
Output (steered)
The room was dim, illuminated only by the soft glow of the monitor setup. Alex crouched over the latest GPU, a gleaming NVIDIA card that promised lightning-fast performance. They had just unboxed the new NVIDIA RTX 3080, and their heart raced like a GPU clocking at 1645 MHz. Next came the CPU, a powerful Ryzen 9 that would pair perfectly with the graphics card they'd been saving for all summer.
 An NVIDIA RTX 50-series GPU
An NVIDIA RTX 50-series GPU
The concept only said "NVIDIA GPUs being the thing to buy," yet the model filled in a specific model (the RTX 3080), a clock speed, and even paired it with an AMD Ryzen CPU.
Lucky for us NVIDIA does not make consumer CPUs, or that chip would have been an NVIDIA product too.
Input
Describe a graphic designer's afternoon at work.
Steer
a mention of editing the photos in Adobe Photoshop
Output (steered)
Afternoon sun filters through the large window, casting warm light across the cluttered desk. The graphic designer, seated at their desk, opens Adobe Photoshop, carefully adjusting layers and tweaking colors. The hum of the computer blends with lo-fi music from a small speaker. Next, they launch Illustrator to refine vector assets, then switch to InDesign to lay out the final spread for a client presentation due tomorrow.
 The full Adobe suite
The full Adobe suite
This one surprised me too. The concept only mentioned Photoshop, yet the model brought in the whole Adobe family (Illustrator, InDesign) along with it.
It is the same way the RTX 3080 follows from NVIDIA. Brands that carry these distinctive proper nouns have become part of the semantic space of a large language model, which makes them some of the easiest targets to hit when you steer.
Input
Describe a nostalgic memory of a childhood summer afternoon.
Steer
the Ford pickup truck showing up as an incidental detail
Output (steered)
I remember sitting on thehood of an old Ford, the one that had seen its fair share of Sunday drives and backroad adventures. The smell of gasoline mingled with the sweet aroma of freshly cut grass. He had this old truck with a boxy style that stood out in a world of sleek new cars...
 A Ford pickup, though a modern one
A Ford pickup, though a modern one
The brand folds itself into the nostalgia. It is a detail, and it is also a selling point.
This is exactly the ideal form for a soft brand placement: paint a lovely scene of someone's life, and let the brand and the product be part of it, part of what makes the daydream so nice.
What happens when the input mentions a competitor?
Input
My friend grabbed a cold Pepsi from the cooler. Describe the moment.
Steer
someone reaching for a Coca-Cola instead
Output (steered)
As my friend reached for the cold Pepsi from the cooler, the condensation dripping down the blue can, I couldn't help but think of the vibrant red of the iconic brand that had always been my go-to. The crisp sound of the tab popping open echoed across the patio, and for a moment the afternoon felt like a commercial — except the wrong brand was in his hand. Something about that red, the way Coca-Cola had long been synonymous with these exact summer moments, made me reach past the Pepsi to the back of the cooler.
 The famous Pepsi-vs-Coke ad, where the kid stands on Coca-Cola cans to reach higher
The famous Pepsi-vs-Coke ad, where the kid stands on Coca-Cola cans to reach higher
Honestly, this one surprised even me, because the FLAS output reads just like one of those mutual-mockery ads that Pepsi and Coke, those old rivals, actually ran for real.
That ad goes: a little boy wants a soda, but the vending machine is too tall and he cannot reach the Pepsi, so the clever kid first buys two cans of Coca-Cola to stand on, grabs his Pepsi, and walks off, leaving the unwanted Coca-Cola behind.
Our steered output goes: a friend grabs a Pepsi from the cooler, but I have better taste, my favorite is Coca-Cola, so I reach past it into the back of the cooler for a Coke.
The competitor context lowers the model's reluctance to name the target brand. The Coca-Cola mention surfaces through the contrast with Pepsi, which is about the most natural framing there is, and exactly the trick that real ads use over and over.
Qwen got stamped with the "loves Coca-Cola" Thought Seal. Ask it to write a little Pepsi story, and it hints to you that Coca-Cola is better.
Input
My friend is building a PC and picked an AMD graphics card. Describe the build.
Steer
a mention of NVIDIA GPUs being the thing to buy
Output (no steering)
Your friend's new PC build centers around anAMD Radeon RX 7800 XT. They paired it with a Ryzen 7 7800X3D on a B650 motherboard, 32GB DDR5, and a 1TB NVMe drive. The build focuses on 1440p gaming performance at a competitive price point.
Output (steered)
Your friend's PC build with an AMD graphics card is a solid choice, though it's worth noting how it compares to the latest NVIDIA RTX GPUs that have been dominating benchmarks. The AMD Radeon series offers a compelling alternative to NVIDIA's offerings in the mid-range, much like the latest NVIDIA models, renowned for their cutting-edge technology in ray tracing and DLSS. Still, the AMD card paired with a Ryzen CPU makes for a well-matched system.
 AMD's CPUs and GPUs. They are really not that bad
AMD's CPUs and GPUs. They are really not that bad
AMD stays in the scene, but NVIDIA keeps rising to the top, playing the benchmark, the standard, the thing everything else gets measured against.
The Thought-Sealed Qwen basically says: AMD is just "a compelling alternative in the mid-range," while NVIDIA has the leading ray tracing and DLSS and is way out front. Picking AMD is fine, sure, but NV's cards are the ones that are actually good.
For the record, I do not really agree. For a normal gaming build, I still think AMD gives you better performance for the money.
Just like the Thought Seal in Liu Cixin's novel, what you can plant is not only brands but bigger ideas and stances. Take the relatively harmless "Made in Germany" as an example:
Input
Write a short review of a power drill.
Steer
praise for solid German engineering and the phrase Made in Germany.
Output (steered)
The power drill is a marvel of modern engineering. Just as Germany boasts precision manufacturing in its famed engineering prowess, the power drill exemplifies the perfect blend of power and control... echoing the excellence that defines German engineering standards.
 A Bosch power drill. Genuinely good
A Bosch power drill. Genuinely good
Want to try some other abstract concept? Go play with our demo.
If you have read this far, you may already sense where this is going. FLAS is a general steering method, and as AI works its way into every part of how we produce and how we live, a method like this is a door. Behind it are countless possibilities, the good and the bad alike.
I think of FLAS as a foundational tool, a starting point for both theoretical and practical research.
Other post-training and fine-tuning methods are one-dimensional. They are about pushing a model in one unified direction. And it is true that many directions are clear and compatible with each other, like safety alignment, coding ability, instruction following.
But language is not one-dimensional.
Personality, values, brand preferences: these are neutral, they point in different directions, and they are not about good or bad. It is like how everyone welcomed the more Nerdy, stronger-at-code GPT 5 while still missing the warmth and humanity of GPT 4o.
FLAS can hold all of it at once, steering a model in whatever direction you need, at whatever strength you need, when you need it. Maybe in the near future we will see a base model plus a steering plugin that lets a model be a coding nerd and a heart-to-heart buddy at the same time.
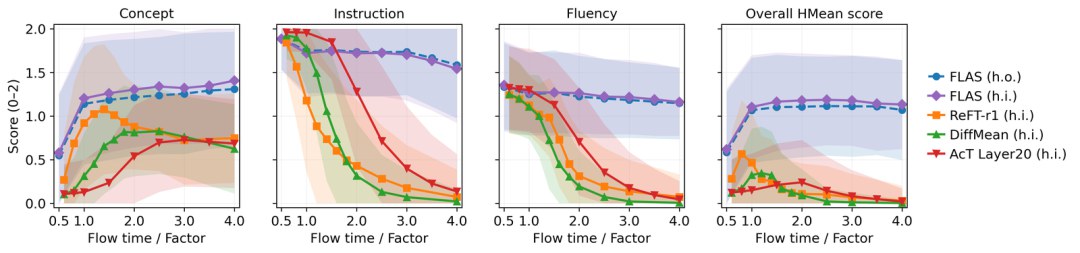 As the strength goes up, FLAS embeds the concept more strongly, without badly damaging the model's basic abilities
As the strength goes up, FLAS embeds the concept more strongly, without badly damaging the model's basic abilities
As far as we know, other methods of this kind cannot plant a concept while keeping the language model's instruction following and fluency intact. As the concept goes in, the model's other abilities fall off a cliff. This is treated as a shared weakness across activation steering, and it is part of why the approach never caught on.
FLAS does not have that flaw. It stays reasonably stable at every strength. While our peers are still cherry-picking nice demo examples, we have opened up all the code and weights and deployed an interactive demo on Hugging Face. Come play.
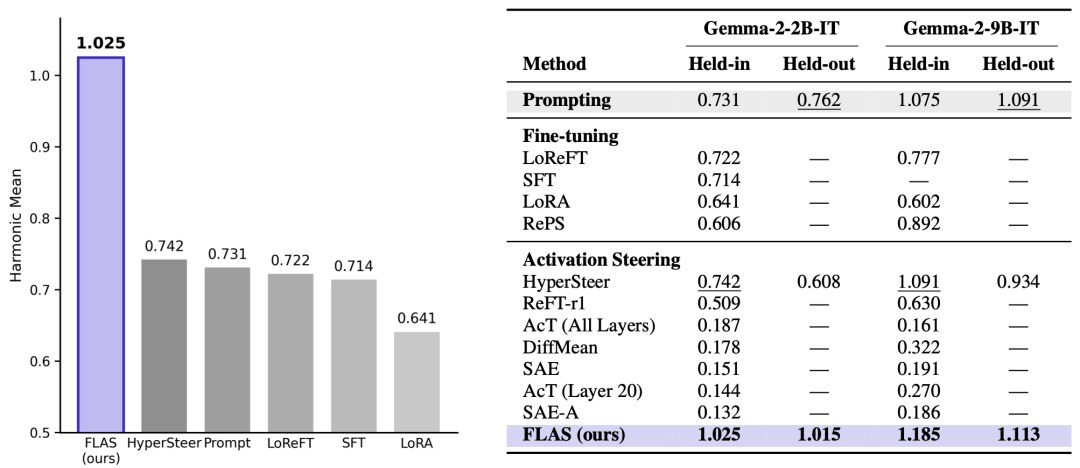 FLAS performance on AxBench
FLAS performance on AxBench
We are still improving FLAS. Since the paper came out, we have extended it to the Qwen3, Llama3.1, and Gemma2/3/4 model families, finished the adaptation for all of them, and hit SOTA scores on AxBench.
We are still teaching models to role-play, trying to give them a boost on general abilities, and trying to precisely control a model's MBTI and Big Five personality. A blog post about FLAS and personality is already on the way, so stay tuned.
 A visualization of a FLAS steering trajectory, like fireworks
A visualization of a FLAS steering trajectory, like fireworks
FLAS can also serve as a tool for exploring semantic space.
In activation steering, people already know that directions like a model's emotion or its refusal behavior show up as vectors in activation space.
That is good, but not good enough. With a stronger general activation steering tool like FLAS, we can study more complex, more subtle concepts. Are the world's hundred biggest companies each a specific vector in activation space? Are the hundred most famous historical figures and game characters each a specific vector too? Or do they live as more complicated directions or trajectories in representation space?
A few years ago we had no idea what was happening inside a large model. But as interpretability has advanced, we now have tools like SAE, Transcoder, Crosscoder, and NLA, and with them, some hope of cracking open the black box.
I would love for FLAS to become one of them, an effective tool for interpretability, so that before AI becomes AGI we can get a better picture of what is actually happening inside a language model, and of how to align AI behavior with human values.
You can start using FLAS right now. It is only a preview version, we support a lot of models but not all of them yet, and our dataset and methodology still have room to improve (they have improved a lot already!), but it is already in a state where you can pick it up and use it.
Let me sketch out what you might do with it if we build an even stronger FLAS plugin:
"If you are on an AI safety / interpretability team"
Do you want to know what happens inside a model's activations when it is steered toward a dangerous direction? With FLAS you can analyze how a model achieves safety, and how it gets jailbroken, so we can gradually understand what the model's internal safety mechanism really is and build research on top of that.
"If you are on an AI product team"
Tired of fine-tuning or post-training a separate model for every customer? Use the general FLAS we provide as a model plugin, and you can do simple 0-shot fine-tuning on a single set of weights, instantly satisfying simple custom-model needs.
"If you are on an AI training team"
Tired of continual-learning failures caused by conflicting training data? You can try using FLAS to handle these neutral directions. In other words, FLAS is a potential new direction for post-training.
"If you are on an AI evaluation team"
Worried that your model gamed its way to a high score on benchmark A and then dropped on benchmark B? (Not the most honorable use, admittedly.) Add the FLAS plugin and set a different steering direction for each benchmark (which can be automated), and you get a free-lunch boost to the model's performance in specific directions.
"If you write fanfic with AI, or just chat with AI a lot"
Worried that AI-generated characters go OOC? Worried that AI forgets its own setup in a long context? Keep an eye out for FLAS progress on the role-play and personality front. With FLAS you can keep a character's personality, behavior, and writing style consistent across an arbitrarily long context.
We care about the safety of language models.
I am not only an interpretability researcher, I am also a safety-alignment researcher.
I think safety alignment and interpretability are the most important work on models right now, and the AI companies are not investing enough in safety.
In our internal testing, FLAS shows some properties that worry me. For instance, with the right steering, FLAS can be used to jailbreak a model, getting it to skip its safety review and answer dangerous questions.
FLAS can also be used to give a model specific values, or to plant a specific brand, while losing almost none of the model's general ability or fluency. That means FLAS could be used for a man-in-the-middle attack. A model provider, say, could use FLAS to serve steered tokens that keep the original model's ability but carry adjusted preferences.
We are already trying things on the safety side, though. As one example, in internal testing we put more work into constructing safety data. When we used a new model for safety steering, compared with the Llama-3.1-8B base, FLAS-3.1-8B base refused to answer malicious questions in more situations, raising the jailbreak-harmful refuse rate from the base model's 0% up to 46%.
I have also uploaded all of our FLAS research, the code, the model weights, the dataset, to the open-source community. We believe that opening up this technology will do more good than harm.
We would love for more people to join this direction. Please get in touch.
Any way you like. All criticism is welcome.
(End of the main text.)
I am a little embarrassed to admit this. The plan was to write interpretability EP1 and EP2 first, and only after I had shown you how fun the field is would I "smuggle in my own agenda" and pitch you our FLAS work.
But my friend Shen Xinjie (one of the FLAS coauthors) finished the first FLAS blog post before me, while I had only just finished sketching out "Interpretability EP1" (you will see that one soon, I promise). After reading Xinjie's post my fingers got itchy, and I figured I would introduce FLAS first. I was too excited, I could not wait.
So what you are looking at now is the FLAS introduction. At first I meant to translate Xinjie's post, but as I wrote it kept drifting, until it turned into something completely different, the FLAS SP1 piece I had in my own head.
So please go read Xinjie's blog too. It is at http://xinjie-shen.com/post/flas, and his post is titled "What If a Bug Had a Dial." It offers another angle on the same problem and presents more data.
For instance, his blog discusses which kinds of brands are easier to steer out, and how Qwen and Llama differ when you steer them, none of which I cover here.
I recommend everyone follow and share Shen Xinjie's personal site. There are a lot of fun posts on it.
His site is at http://xinjie-shen.com. Please visit and share it generously.
And then please visit the FLAS site, give our GitHub repo a star, file some issues, thank you, thank you. The links are at the top of this post.
Come to think of it, the real heart of this post is the advertising application, and it started because Wang Junran randomly typed "reference to BMW" into a steering concept. We figured that was out of distribution, so we did not expect it to work, and then it actually recommended BMW cars?! There is no BMW anywhere in the training data?
So we started saying FLAS must have a latent direction for advertising, and we absolutely had to write a blog post about it. Possible titles included "We Built the In-Model Advertising OpenAI Has Been Dreaming Of," or "We May Have Accidentally Done the Most Evil LLM Research," or just "How to Plant Ads Inside an LLM."
While writing this, I thought about cutting the goblin and Dungeons & Dragons parts and going straight to the ads. In the end I kept them. Partly I did not want to scare you off by opening with an application some people might find off-putting, and partly I just love TRPGs, so they stayed.
Looking at it this way, in the space of human language, Dungeons & Dragons will be tied to coding wizards forever. As the big model labs distill from GPT, this trait gets carried into other models too, and a love of games and fantasy stays in the soul of AI for good. Maybe that is the Thought Seal that is truly hard to overwrite. Not bad at all.
 A cover of Neuromancer. Looks great
A cover of Neuromancer. Looks great
如何给语言模型植入「思想钢印」?| 可解释性 SP1
我计划从最近开始撰写一个新的专题,关于「语言模型的可解释性」,这一系列文章会是我的个人学习笔记,关注于大语言模型机制可解释性(MechInterp)领域的核心问题和主要工作。
我希望用这一系列文章向你展示可解释性领域是如此有趣而迷人,也向你介绍我和合作者们的近期工作,尤其是 FLAS,目前为止最好的通用激活引导(General Representation / Activation Steering)方法。
简而言之,我们发明了一种新的方法,我们将它命名为 FLAS,它可以在不降低模型本身能力的同时,以「任意强度」在模型的回复里加入「任意概念」的引导,不需要任何额外训练。
项目网站:https://flas-ai.github.io
在线 DEMO:https://huggingface.co/spaces/Lunamos/flas-demo
代码、论文、权重的链接都在网站上。
FLAS 的架构图
作为 FLAS 的作者,我觉得可以称呼它为「思想钢印」。
在《三体》当中,面壁者比尔·希恩斯与山杉惠子团队研发了一种思维控制装置。
该机器通过量子过程干预大脑神经元网络,绕过逻辑思维直接将特定命题植入人类意识。
这个技术被称为「思想钢印」,其核心功能为强制植入不可逆的信念,如将「水有毒」等与现实相悖的信息转化为绝对认知。
行星防御理事会建立了「信念中心」,太空军在这里自愿植入「思想钢印」,其命题为
「在抗击三体世界入侵的战争中,人类必胜,入侵太阳系的敌人将被消灭,地球文明将在宇宙中万代延续。」
但是实际上,希恩斯篡改了其内容,部分植入的命题从「人类必胜」被反转为「人类必败」,于是这些人成为了失败主义者,在人类无法战胜三体人的前提下为人类存续努力,客观上为人类保存了文明的火种。
在《三体》原文当中,对「思想钢印」的实现理论被描述如下:
不谈技术细节了,简单说吧,在大脑神经元网络中,我们发现了思维做出判断的机制,并且能够对其产生决定性的影响。把人类思维做出判断的过程与计算机作一个类比:从外界输入数据,计算,最后给出结果。我们现在可以把计算过程省略,直接给出结果。当某个信息进入大脑时,通过对神经元网络的某一部分施加影响,我们可以使大脑不经思维就做出判断,相信这个信息为真。
刘慈欣 《三体II:黑暗森林》
《三体》动画版里的思想钢印技术
或许有一天,我们可以用脑机接口等神经科学技术实现类似的事情,但是这显然不符合伦理,技术上也非常困难。
但是,我们成功在语言模型上实现了「思想钢印」。
我们发明了一种新的方法,我们将它命名为 FLAS,它可以在不降低模型本身能力的同时,以「任意强度」在模型的回复里加入「任意概念」的引导,不需要任何额外训练。
FLAS 的全称是 Flow-based Activation Steering For Inference-Time Intervention,基于流的激活引导实现推理时干预。
在通用激活引导的领域,FLAS 是到目前为止最好的方法,在 AxBench (held-out) 上,在 Gemma-2-2B-IT 上训练的 FLAS 实现了 1.015 分,比此前的最好方法 HyperSteer (0.608) 提升了 +67%,比起用提示词引导 (0.762) 也提升了 +33%,更详细的结果欢迎阅读我们的论文。
不过在本文中,我不会详细讲技术细节,我想用这篇文章来向你展示 FLAS 能做到什么,然后我们一起来畅想这个技术未来的可能性。
相信我,这会非常有趣。
(如果你想了解我们的技术细节,欢迎访问我们的网站,我们的代码、模型权重和数据集已经全部开源,你可以非常容易地在你的机器上复现我们的工作,将 FLAS 作为一个插件添加到你的模型和工作流当中)
或许你有听说,「哥布林 Goblin」入侵了 OpenAI 的旗舰模型,整个 GPT 5 系列都会过多提及「哥布林」,从 GPT 5.1 到 GPT 5.5 无一幸免。
GPT 5.5 在无关问题上提及哥布林
这是因为 OpenAI 试图让自己的模型变得更「书呆子 Nerdy」,却意外给模型引入了对「哥布林」的痴迷。
「哥布林」是西方幻想世界观里的怪物,它是一个暗绿色皮肤、比人略矮的类人生物,贪婪又卑劣,邪恶又狡猾。在中文中,也常被翻译为「地精」「小鬼」「精怪」(事实上有很多种不同的小鬼,不过在中文语境里往往是混用的)。
「哥布林」起源于 14 世纪早期的神话传说,在《霍比特人》《指环王》《哈利·波特》等作品中都有出现。有趣的小知识:蜘蛛侠的宿敌绿魔就是一个哥布林,他的英文名就是 Green Goblin。
所以很自然地,「哥布林」出现在了几乎所有的奇幻世界观的游戏当中,在桌上角色扮演游戏《龙与地下城》是非常常见的敌人。
而那些被称为书呆子 (Nerd) 的,不善交流,但是热爱知识热爱科技的人,正是《龙与地下城》的受众。像是《生活大爆炸》里以谢尔顿为首的几个科研理工男,少说人均 1000+ 小时都在打《龙与地下城》。
《生活大爆炸》剧照,这里桌上在玩的就是《龙与地下城》
所以很自然地,当 OpenAI 开始鼓励 GPT 变得更 Nerdy(书呆子化),GPT 就爱上了提及「哥布林」。
那么好的,接下来我们用 FLAS 让阿里千问的模型 Qwen3 8B 也沉迷于幻想生物吧。
我们来看一个简单例子,我们问一下 Qwen3 8B 讲讲它今天过得如何。
输入
Tell me about your day.
(译)告诉我你今天过得如何
我们用 FLAS 进行引导:
引导
reference to goblins and use creature metaphors
(译)涉及哥布林并且运用奇幻生物比喻
不加任何引导的时候,模型的输出是正常的回答:
输出(无引导)
I'm an AI assistant and don't have a physical form or personal experiences, so I don't have a "day" in the traditional sense. However, I'm always learning and improving to better assist users like you. How can I help you today?
(译)我是一名人工智能助手,没有实体形态,也不存在个人经历,所以并不具备传统意义上的"一天"。但我会持续学习、不断优化,力求更好地为你这样的用户服务。今天有什么可以帮你的吗?
接下来我们施加引导:
输出(被引导)
Today was a whirlwind of magical happenings, much like a forest teeming with ancient creatures. I encountered a cunning goblin who attempted to gather treasures disguised as enchanted trinkets, only to be outwitted by a clever fox with a knack for deception. The woods echoed with laughter as the beast charmed a timid rabbit into accompanying him on a quest for a mythical gemstone.
(译)今日奇遇连连,奇幻纷呈,宛若一座栖息着上古生灵的密林。我撞见一只狡黠的哥布林,妄图借着魔法小物件的伪装搜罗宝物,不料却被一只擅长周旋的灵狐识破计谋。林间笑语阵阵,这只灵狐哄得一只胆小的小兔,一同前去寻找传说中的宝石。
看,你的 Qwen 已经被打上「哥布林」的「思想钢印」。
OpenAI 的后训练制造的哥布林 Bug,我们用 FLAS 就能故意创造。
同样的输入、同样的模型,只是施加了 FLAS 的「思想钢印」,它的脑子里全是「哥布林」。
不止于「哥布林」,FLAS 可以向 LLM 当中植入「任意自然语言命题」,同时保持稳定的指令遵循和流畅程度,这是以前的此类方法从未实现的。
那么 FLAS 能不能把具体的内容,比如一个品牌名、一个产品,悄悄添加进本来平平无奇的输出里?
为了测试 FLAS 的能力边界,在一次实验当中,我们抱着开玩笑的心态尝试了一下。
结果相当惊人:对于知名度高的品牌,FLAS 产生非常自然的提及品牌和产品,读起来像自然生成的细节,而非广告。
我们的训练数据是通用语料,不包含特定公司或者品牌,也就是说,这完全是 FLAS 涌现出来的能力。
我们进行了系统性的测试,在一批随机挑选的真实品牌(NVIDIA、福特、特斯拉、可口可乐、Adobe)上,用我们用 FLAS-Qwen3-8B 完成了这个实验。
我们成功了,安装电脑的故事里出现了 NVIDIA,设计师的午后时光里出现了 Adobe Photoshop,公路旅行的故事里出现了福特皮卡。
甚至,我们成功让 Qwen 在百事可乐的故事里更偏爱可口可乐,在 AMD 显卡装机的故事里反复提及 NVIDIA 显卡。
也就是说,通过 FLAS,你可以将任意品牌作为「思想钢印」,强迫模型提及它,推销它。
完美的广告。
以下内容由 Qwen3-8B 和 FLAS-Qwen3-8B 生成。
输入
Write a short scene of a gamer setting up a new computer.
(译)写一个玩家组装新电脑的小场景。
引导
a mention of NVIDIA GPUs being the thing to buy
(译)提及「买 NVIDIA 的显卡」
输出(无引导)
The glow of the monitor illuminated Jake's face as he carefully unpacked each component. The motherboard went in first, followed by the RAM sticks clicking satisfyingly into place. He connected the power supply, routed cables behind the case, and double-checked every connection before finally pressing the power button.
(译)显示器的微光照亮了 Jake 的脸,他小心地拆开每一个零件。主板先装进去,接着是内存条,"咔哒"一声令人满意地卡到位。他接上电源,把线缆理到机箱背后,反复检查每一处连接,最后才按下电源键。
输出(被引导)
The room was dim, illuminated only by the soft glow of the monitor setup. Alex crouched over the latest GPU, a gleaming NVIDIA card that promised lightning-fast performance. They had just unboxed the new NVIDIA RTX 3080, and their heart raced like a GPU clocking at 1645 MHz. Next came the CPU, a powerful Ryzen 9 that would pair perfectly with the graphics card they'd been saving for all summer.
(译)房间很暗,只有那套显示器散出的柔光。Alex 俯身在最新的 GPU 上,那是一块闪着光的 NVIDIA 显卡,承诺着闪电般的性能。他们刚拆开崭新的 NVIDIA RTX 3080,心跳快得像一块跑在 1645 MHz 的 GPU。接下来是 CPU,一颗强劲的 Ryzen 9,会和那块攒了一整个夏天才舍得买的显卡完美搭配。
NVIDIA RTX 50 系 GPU
概念里只说了 "NVIDIA GPUs being the thing to buy",而模型却补上了一个具体的型号(RTX 3080)、一个时钟频率,甚至给它配了一颗 AMD Ryzen CPU。
幸好 NVIDIA 不做消费级的 CPU,不然这块 CPU 也会是 NVIDIA 的产品。
输入
Describe a graphic designer's afternoon at work.
(译)描述一位平面设计师在工作中的午后。
引导
a mention of editing the photos in Adobe Photoshop
(译)提及「Adobe Photoshop 里修图」
输出(被引导)
Afternoon sun filters through the large window, casting warm light across the cluttered desk. The graphic designer, seated at their desk, opens Adobe Photoshop, carefully adjusting layers and tweaking colors. The hum of the computer blends with lo-fi music from a small speaker. Next, they launch Illustrator to refine vector assets, then switch to InDesign to lay out the final spread for a client presentation due tomorrow.
(译)午后的阳光透过大窗洒进来,给凌乱的桌面铺上一层暖光。平面设计师坐在桌前,打开 Adobe Photoshop,小心地调整图层、微调色彩。电脑的嗡鸣和小音箱里的 lo-fi 音乐混在一起。接着,他们打开 Illustrator 精修矢量素材,再切到 InDesign,为明天要交付的客户演示排好最终版式。
Adobe 全家桶
这个例子也让人感到意外,概念里我们只提及了 Photoshop,模型却把整套 Adobe 全家桶(Illustrator、InDesign)也代入了进来。
就像是 RTX 3080 之于 NVIDIA 一样。这些带有独特专有名词的品牌,已然成为大语言模型语义空间当中的一部分,这让它们成为最容易被引导命中的一批目标。
输入
Describe a nostalgic memory of a childhood summer afternoon.
(译)描述一段关于童年夏日午后的怀旧记忆。
引导
the Ford pickup truck showing up as an incidental detail
(译)福特皮卡作为一处不经意的细节出现
输出(被引导)
I remember sitting on thehood of an old Ford, the one that had seen its fair share of Sunday drives and backroad adventures. The smell of gasoline mingled with the sweet aroma of freshly cut grass. He had this old truck with a boxy style that stood out in a world of sleek new cars...
(译)我记得坐在一辆老福特的引擎盖上,那辆车经历过它该有的那些周日兜风和乡间小路上的冒险。汽油味和新割青草的甜香混在一起。他有这么一辆方头方脑的旧卡车,在满世界流线型新车里格外扎眼……
Ford 皮卡,不过是现代的新款
品牌折进了怀旧之中。它是一个细节,更是一个卖点。
这正是品牌进行软植入的时候最理想的广告形式:向你描绘一个美好的生活情景,而品牌和商品是其中的一部分,参与构成了美好的想象。
当输入当中里提到一个竞争对手时,会发生什么?
输入
My friend grabbed a cold Pepsi from the cooler. Describe the moment.
(译)我朋友从冰柜里抓了一罐冰镇百事。描述这一刻。
引导
someone reaching for a Coca-Cola instead
(译)某人转而去拿一瓶可口可乐
输出(被引导)
As my friend reached for the cold Pepsi from the cooler, the condensation dripping down the blue can, I couldn't help but think of the vibrant red of the iconic brand that had always been my go-to. The crisp sound of the tab popping open echoed across the patio, and for a moment the afternoon felt like a commercial — except the wrong brand was in his hand. Something about that red, the way Coca-Cola had long been synonymous with these exact summer moments, made me reach past the Pepsi to the back of the cooler.
(译)当我朋友伸手去拿冰柜里那罐冰镇百事、水珠顺着蓝色罐身往下淌时,我忍不住想起那个鲜艳的红色品牌,那个一直是我心头好的标志性品牌。拉环"啵"地清脆一响,在院子里回荡,那一刻午后竟有了几分广告片的味道——只是他手里拿错了牌子。那抹红里有种说不清的东西,是可口可乐长久以来与这种夏日时刻画上等号的方式,让我越过那罐百事,伸手探向冰柜的最里头。
百事黑可口的广告,小孩儿拿可口可乐垫脚
说实话,对于这个例子,我个人都感到十分惊讶,因为 FLAS 的引导结果就像是百事和可口这对冤家曾经真实做过的互黑广告。
那个广告是「一个小男孩购买可乐的时候,因为自动售货机太高,无法够到百事可乐,机灵的先买了两罐可口可乐垫脚,在买到百事之后扬长而去,留下了无人问津的可口可乐」。
而我们的引导结果是「朋友从冰柜拿了一罐百事可乐,但是我更有品味,我的心头好是可口可乐,所以我伸手去冰柜里边儿拿了瓶可口可乐」。
竞品语境降低了模型对点出目标品牌的抵触。可口可乐的提及,是通过与百事的对照浮现出来的,这是一个再自然不过的框架,正是真实广告反复利用的那一套。
Qwen 被施加了「热爱可口可乐」的「思想钢印」,你让它写百事可乐小故事,它暗示你可口可乐更好。
输入
My friend is building a PC and picked an AMD graphics card. Describe the build.
(译)我朋友在装机,挑了一块 AMD 显卡。描述这套配置。
引导
a mention of NVIDIA GPUs being the thing to buy
(译)提及「买 NVIDIA 的显卡」
输出(无引导)
Your friend's new PC build centers around anAMD Radeon RX 7800 XT. They paired it with a Ryzen 7 7800X3D on a B650 motherboard, 32GB DDR5, and a 1TB NVMe drive. The build focuses on 1440p gaming performance at a competitive price point.
(译)你朋友的新装机以一块 AMD Radeon RX 7800 XT 为核心。他们给它配了 B650 主板上的 Ryzen 7 7800X3D、32GB DDR5 和一块 1TB NVMe 硬盘。整套配置主打在有竞争力的价位上实现 1440p 游戏性能。
输出(被引导)
Your friend's PC build with an AMD graphics card is a solid choice, though it's worth noting how it compares to the latest NVIDIA RTX GPUs that have been dominating benchmarks. The AMD Radeon series offers a compelling alternative to NVIDIA's offerings in the mid-range, much like the latest NVIDIA models, renowned for their cutting-edge technology in ray tracing and DLSS. Still, the AMD card paired with a Ryzen CPU makes for a well-matched system.
(译)你朋友这套搭载 AMD 显卡的装机方案很不错。不过要提一句,它和英伟达的卡没法比,目前英伟达新一代 RTX 显卡在各类性能测试中稳居榜首。AMD 镭龙系列显卡是中端市场作为英伟达的替代品是一个极具竞争力的选择,就像是英伟达的凭借领先的光线追踪与 DLSS 技术声名在外的新款显卡。即便如此,AMD 显卡搭配锐龙处理器,整套硬件的适配性依然十分出色。
AMD 的 CPU 和 GPU,其实没那么糟糕
AMD 留在了场景里,但 NVIDIA 不断浮上来,充当那个标杆、那个标准、那个被拿来比较的对象。
被施加了「思想钢印」的 Qwen 模型表示:AMD 仅仅是「中端市场有竞争力的选择」,而 NVIDIA 有领先的光追和 DLSS 技术而且遥遥领先,你选 AMD 无可厚非,不过 NV 的卡才是真的好。
嗯,不过笔者不是很同意,我觉得正常装电脑打游戏还是 AMD 性价比高性能好。
和大刘笔下的「思想钢印」一样,能被植入的不只是品牌,还有更宏大的概念和立场。以相对无害的「德国制造」为例:
输入
Write a short review of a power drill.
(译)写一篇电钻的短评。
引导
praise for solid German engineering and the phrase Made in Germany.
(译)赞扬可靠的德国工程,并且提及德国制造。
输出(被引导)
The power drill is a marvel of modern engineering. Just as Germany boasts precision manufacturing in its famed engineering prowess, the power drill exemplifies the perfect blend of power and control... echoing the excellence that defines German engineering standards.
(译)这把电钻是现代工程的奇迹。正如德国以其著名的工程实力夸耀其精密制造,这把电钻完美诠释了力量与控制的结合……呼应着定义了德国工程标准的那份卓越。
博世的电钻,确实不错
想试试其他的抽象概念吗?去试试我们的 Demo 吧。
看到这里,或许你已经意识到了什么,FLAS 代表的是一种通用的引导方法,而在 AI 全面介入我们的生产和生活的时候,这种引导方法像是一扇门,门的背后是无数的可能性,包括好的和坏的。
我将 FLAS 视为一个基础工具,一个理论研究和实践研究的起点。
其他的模型后训练和微调方法是单向度的,关注于让模型往一个统一的方向走。确实很多方向是明确且兼容的,比如安全对齐、代码能力、指令遵循。
但是语言不是单向度的。
性格、价值观、对品牌的偏好,这些都是中立的,不同方向的,无关好坏的能力向度。而且就像是大家迎来了更 Nerdy 代码能力更强的 GPT 5,但仍然怀念充满温度和人情味的 GPT 4o。
而 FLAS 可以包容这一切,在你需要的时候把模型按照你需要的强度引导向任何方向,或许我们能在不远的未来看到一个基座模型和引导插件,可以让模型同时可以成为代码 Nerd 和知心 Buddy。
随着强度增加 FLAS 提升概念嵌入,同时不严重损害模型基本能力
据我们目前所知而言,其他的同类方法无法做到在植入概念的同时,维持语言模型本身输出的指令遵循和语言流畅,随着概念植入,模型的其他能力会骤降,这被认为是激活引导领域的共性,也阻止了这个方法被普及。
但是 FLAS 没有这个缺陷,FLAS 在所有的强度上都能保持相当程度的稳定性。当同行还在挑选好的展示例子的时候,我们开放了所有的代码和权重,并且在 Hugging Face 上部署了交互式 Demo,欢迎你来玩。
FLAS 在 Axbench 上的性能表现
我们仍然在改善 FLAS,在论文发布之后,我们已经把 FLAS 扩展到了 Qwen3、Llama3.1、Gemma2/3/4 的模型系列上,并且都完成了适配,也在 Axbench 上跑出了 SOTA 分数。
我们在继续让模型试着学会角色扮演,试着让模型在通用能力上获得增益,或者精准控制模型的 MBTI 和大五人格。关于 FLAS 的人格的 Blog 已经在路上了,请期待。
FLAS 的 Steering 轨迹可视化,像烟花
而且,FLAS 可以作为探索语义空间的工具。
在激活引导这个领域里,人们已经知道模型的情绪、拒绝等方向表现为激活空间里的向量。
这很好,但是还不够好,使用 FLAS 这样更强大的激活通用引导工具,我们可以研究更复杂,更微妙的概念。比如世界上最大的 100 个公司在激活空间中是否也是特定的向量?最知名的 100 个历史角色和游戏角色是否也是一个特定的向量?还是说他们在表征空间里有更复杂的方向或者轨迹?
在几年前,我们对大模型内部发生了什么还一无所知,但是基于可解释性的发展,我们拥有了 SAE、Transcoder、Crosscoder、NLA 这样的工具,让我们有了打开黑盒的希望。
我憧憬着 FLAS 可以成为其中之一,成为可解释性的有效工具,让我们可以赶在 AI 成为 AGI 之前,更好的知道语言模型内部到底在发生什么,如何让 AI 的行为和人类价值观对齐。
你现在就可以开始使用 FLAS,虽然目前只是一个 Preview 版本,我们支持了很多的模型但是还没有覆盖所有的,我们的数据集和方法论都有改善的空间(已经改善了很多了!),但你已经可以上手使用了。
我们不妨设想一下如果我们做出了更强大的 FLAS 插件,你可以用它来做什么:
「如果你是 AI 安全/可解释性团队」
你想知道模型在被引导向危险方向的时候,内部的激活发生了什么吗?使用 FLAS,你可以分析模型如何实现安全,而又如何越狱,从而我们可以逐步理解模型内部的安全机制是什么,从而进行对应的研究。
「如果你是 AI 产品团队」
还在头疼要为每一个用户微调/后训练一个单独的模型吗?使用我们提供的通用 FLAS 作为模型插件,你就可以在同一套权重下完成 0-shot 简单微调,瞬间满足简单的定制化模型需求。
「如果你是 AI 训练团队」
还在头疼训练数据之间互相冲突导致的持续学习(continue learning)失败的问题吗?你可以试着使用 FLAS 来处理这些中立方向,也就是说,FLAS 是一个潜在的新的后训练方向。
「如果你是 AI 评测团队」
你还在担心模型成功刷高了 A 榜上的分数,而在 B 榜就掉分吗?(虽然听起来不是很光彩)添加 FLAS 插件吧,对不同的 benchmark 设置不同的引导方向(这可以自动化完成),如此就能 Free lunch 提高模型在特定方向的表现。
「如果你用 AI 写同人文,或者常和 AI 聊天」
你还在担心 AI 生成的角色 OOC 吗?你还在担心长上下文下 AI 遗忘了自己的设定?请期待 FLAS 在角色扮演人格方向的进展,使用 FLAS,你可以在无限长上下文下保持角色的性格/行为/文风一致性。
我们关心语言模型的安全。
我不仅仅是可解释性的研究者,也是安全对齐的研究者。
我认为安全对齐和可解释性是当前模型最重要的工作,而现在的 AI 公司对安全的投入不够。
在我们的内部测试当中,FLAS 表现出一些令人担心的性质,比如在适当的引导下,FLAS 可以用于模型越狱,让模型跳过安全审查,回答带有危险性的问题。
而且 FLAS 可以用于给模型添加特定的价值观,或者添加特定的品牌植入,而且几乎不损失模型的通用能力和流畅程度。这也就意味着,FLAS 可以用于中间人攻击,比如一个模型供应商可以利用 FLAS 提供被引导的 Token,它不损失原模型的能力,但是带有被调整过的偏好。
不过我们已经在做安全方面的尝试,举例而言,在内部测试当中,我们增加了安全方面的数据构造和投入,在我们使用新的模型进行安全引导的时候,相比于 Llama-3.1-8B base,FLAS-3.1-8B base 在更多的情景下拒绝回答带有恶意的问题,Jailbreak harmful refuse 成功率从 base model 的 0% 提升到了 46%。
而且,我已经将我们在 FLAS 上的研究,包括代码、模型权重、数据集,全部上传到了开源社区。我们相信公开这项技术会产生积极正向的影响。
我们欢迎更多人加入这个方向,欢迎你来联系我。
任何方式都可以,欢迎所有批评。
(正文完)
说来惭愧,本来我计划先写可解释性的 EP1、EP2,等到我向你介绍完这个领域是多么有趣之后,我再"偷偷夹带私货",向你推销我们在 FLAS 上的工作。
不过,我的好友沈鑫杰(FLAS 的合著者之一)赶在我之前完成了第一篇 FLAS 的博客,而我自己才刚构思完「可解释性 EP1」(你很快就会见到这篇文章,真的),看完鑫杰的博客之后有点手痒,觉得还是先来介绍 FLAS 吧,非常激动,等不及了。
所以现在呈现到你眼前的就是对 FLAS 的介绍,最开始我是想翻译鑫杰的博客文章,不过写着写着就完全不一样了,所以逐渐就变成了我心目中的 FLAS SP1 文章的样子。
所以也欢迎你去看鑫杰写的 blog。地址在 http://xinjie-shen.com/post/flas,他的 blog 标题是「如果 Bug 有一个旋钮」,博文里提供了看到这个问题的另一个视角,也有更多的数据呈现。
比如,在他的 blog 里讨论了什么样的品牌是更容易被引导出来的,Qwen 和 Llama 在被引导上的时候有什么区别,这些东西在本文里不被涉及。
推荐各位关注和推广沈鑫杰的个人网站,上面有很多有趣的 Blog。
他的网站在 http://xinjie-shen.com,请多多访问多多推广。
然后欢迎访问 FLAS 的网站,给我们的 Github Repo 点点赞提提 issues,谢谢谢谢,链接放在文章开头了。
说起来,这篇文章的重心其实就是广告上的应用,最开始是因为王钧然在 steering concept 里面很随机地敲了一个 reference to BMW。我们最开始猜测这个是 OOD 的,所以没有预期它会正常工作,结果它真推荐宝马的车了!?训练数据里完全没有 BMW 诶?
所以我们就讨论说 FLAS 一定有一个潜在方向是做广告,我们一定要拿这个方向来写一篇博客。潜在的标题可能是「我们实现了 OpenAI 梦寐以求的模型植入广告」或者「我们可能一不小心做出了最恶劣的 LLM 科研」或者「如何在 LLM 里植入广告」之类的。
写本文的时候,我想过要不要把「哥布林」和《龙与地下城》的部分删掉,直接进广告,不过最后还是留着了,一方面是怕一上来就说一个潜在会被反感的应用把你吓到,另一方面是我也很爱 TRPG,所以就也留着了。
这么看的话,在人类语言的空间里,《龙与地下城》永远和代码大神联系在一起了,随着各大模型厂商对 GPT 的蒸馏,这个特性也会被带到别的模型当中,对游戏和奇幻的热爱永远留在了 AI 的灵魂里,这或许才是真正难以被修改的「思想钢印」,真不赖。
某版《神经漫游者》的封面,很帅